Die 3-Minuten-Regel: Wie Solounternehmer das „Overthinking“ bei Prompts stoppen und sofort Ergebnisse sehen
Warum nicht jede Aufgabe ein grosses Reasoning-Modell braucht. Wie klare Prompts, kleinere Modelle und einfache Workflows oft schneller ans Ziel führen.


KI ist Infrastruktur geworden. Unternehmen und Behörden nutzen Sprachmodelle täglich: im Kundenservice, in der Verwaltung, in der Dokumentation, bei Recherchen und in der Analyse. Viele Schnittstellen rechnen pro Token ab.
Das Problem lässt sich nüchtern benennen: Overthinking im Output. Sprachmodelle liefern oft mehr Text als nötig: Einleitungen, Wiederholungen, höfliche Übergänge, Zwischenerklärungen und Schlusszusammenfassungen. Für einzelne Anfragen wirkt das harmlos. Bei Tausenden oder Zehntausenden Abfragen pro Monat wird daraus ein Kosten-, Latenz- und Governance-Thema.
In eigenen Praxismessungen liess sich der Token-Verbrauch durch drei Massnahmen um bis zu 72 Prozent senken. Dieser Werthängt vom Modell, vom Anwendungsfall, von der Sprache, vom Prompt-Design und von der technischen Umgebung ab. Aber er zeigt: Wer LLMs produktiv einsetzt, sollte Effizienz nicht dem Zufall überlassen.
1. Das passende Modell für die Aufgabe wählen
Nicht jede Anfrage braucht das stärkste Modell. Einfache Klassifikationen, kurze Zusammenfassungen, Standardantworten oder Routineprüfungen lassen sich meist mit günstigeren und schnelleren Modellen bearbeiten. Reasoning-Modelle sind wertvoll, wenn sie wirklich gebraucht werden: bei komplexer Logik, Mathematik, Architekturentscheidungen, mehrstufigen Analysen oder schwierigen Abwägungen.
Die entscheidende Disziplin heisst Modell-Routing: Welche Aufgabe geht an welches Modell?
Ein Unternehmen, das jede Supportfrage mit einem teuren Reasoning-Modell bearbeitet, verschwendet Budget. Umgekehrt spart es am falschen Ort, wenn komplexe Rechts-, Sicherheits- oder Architekturfragen an ein zu schwaches Modell delegiert werden.
Als Orientierung können öffentliche Leaderboards wie LMArena dienen. Die Plattform basiert auf menschlichen Paarvergleichen und veröffentlicht Rankings aus Nutzerpräferenzen. Das ist nützlich, aber kein Ersatz für eigene Tests. LMArena zeigt Präferenzen in einer offenen Arena; ob ein Modell für einen konkreten Behördenprozess, eine interne Fachanwendung oder einen lokalen Schweizer Use Case geeignet ist, muss separat geprüft werden.
Manuela Frenzel | Inhaberin & CAS AI Prompter
Praxisregel:
Für Standardaufgaben genügt ein schnelles Standardmodell. Für komplexe Analyse, Coding, Mathematik und strategische Entscheidungen lohnt sich ein Reasoning-Modell.
2. Antworten aktiv begrenzen
Viele LLM-Antworten sind länger als nötig. Das liegt an seinem Trainingsziel: hilfreich, vollständig und anschlussfähig wirken. Genau diese Hilfsbereitschaft wird im Betrieb teuer.
Ein einfacher Prompt-Baustein kann helfen:
Sobald die Kernantwort vollständig ist, beende die Antwort. Keine Einleitung, keine Wiederholung, keine Schlusszusammenfassung.
Noch wirksamer wird es, wenn die inhaltliche Anweisung technisch abgesichert wird. Je nach API und Umgebung stehen Parameter wie max_output_tokens, max_tokens, stop oder vergleichbare Stop-Sequenzen zur Verfügung. In lokalen Umgebungen wie Ollama, LM Studio oder Open WebUI lassen sich Ausgabegrenzen ebenfalls setzen, sofern das jeweilige Backend sie unterstützt.
Wichtig ist: Ein zu knappes Limit kann Qualität minimieren. Deshalb sollte nicht pauschal gekürzt werden. Sinnvoll ist ein Grenzwert pro Aufgabentyp: kurze Klassifikation, mittlere Fachantwort, ausführliche Analyse.
Praxisregel:
Nicht „kurz antworten“ schreiben und hoffen. Besser: Antwortziel definieren, maximale Länge setzen, Abbruchbedingung festlegen und anschliessend messen.
Was ist Ollama?
Ollama ist das ideale Werkzeug für Einzelunternehmer, Organisationen und Private. Während es bei vielen gleichzeitigen Anfragen an Effizienz verliert, da es Anfragen weitgehend nacheinander abarbeitet (Serialisierung), punktet es durch seine Zugänglichkeit und den geringen Ressourcenverbrauch auf Consumer-Rechnern.
3. Ausgabeformate erzwingen
Freitext gibt Modellen viel Raum. Das ist für Essays, Beratung und Erklärungen sinnvoll. Für Workflows, Schnittstellen und Behördenprozesse ist es oft ineffizient.
Ein definiertes Ausgabeformat reduziert Spielraum:
Antworte ausschliesslich im folgenden JSON-Format.Gib keinen Text ausserhalb des JSON-Objekts aus.Bei API-Anwendungen ist ein Schema noch stärker. OpenAI beschreibt Structured Outputs als Weiterentwicklung des JSON-Modus: JSON-Modus stellt gültiges JSON sicher, Structured Outputs sollen zusätzlich die Einhaltung des vorgegebenen Schemas absichern.
Für einfache, flache Strukturen ist JSON meist die richtige Wahl: kompakt, maschinenlesbar, API-tauglich. XML kann sinnvoll sein, wenn bestehende Behörden- oder Archivsysteme damit arbeiten, wenn verschachtelte Dokumentstrukturen gebraucht werden oder wenn XSD-Validierung bereits Teil der Umgebung ist.
Praxisregel:
Wo ein KI-Modell die Antwort weiterverarbeitet, sollte das Modell nicht frei formulieren. Es sollte Felder ausfüllen.
Sprache als Kostenfaktor
KI-Sprachkosten einfach erklärt
Warum deutsche Prompts und Antworten teurer abgerechnet werden
Ein übersehener Hebel ist die Sprache. Deutsche Texte können je nach Tokenizer und Textsorte mehr Tokens benötigen als gleichbedeutende englische Texte. Der Grund liegt unter anderem in längeren Wörtern, Komposita und Subword-Zerlegung.
Für Schweizer Unternehmen und Behörden heisst das nicht: Alles auf Englisch umstellen. Bürgerkommunikation, Kundendienst und rechtlich sensible Texte gehören in die Sprache der Zielgruppe. Aber technische Prompts, interne Analyseaufträge, Coding-Aufgaben oder Systemanweisungen können auf Englisch effizienter sein, sofern dadurch keine fachliche Präzision verloren geht.
Praxisregel:
Deutsch dort, wo Verständlichkeit, Rechtssicherheit und Nutzerbezug zählen. Englisch prüfen, wo es um technische Steuerung, interne Workflows oder Entwicklerprozesse geht.
Lokale Modelle, APIs und Skalierung
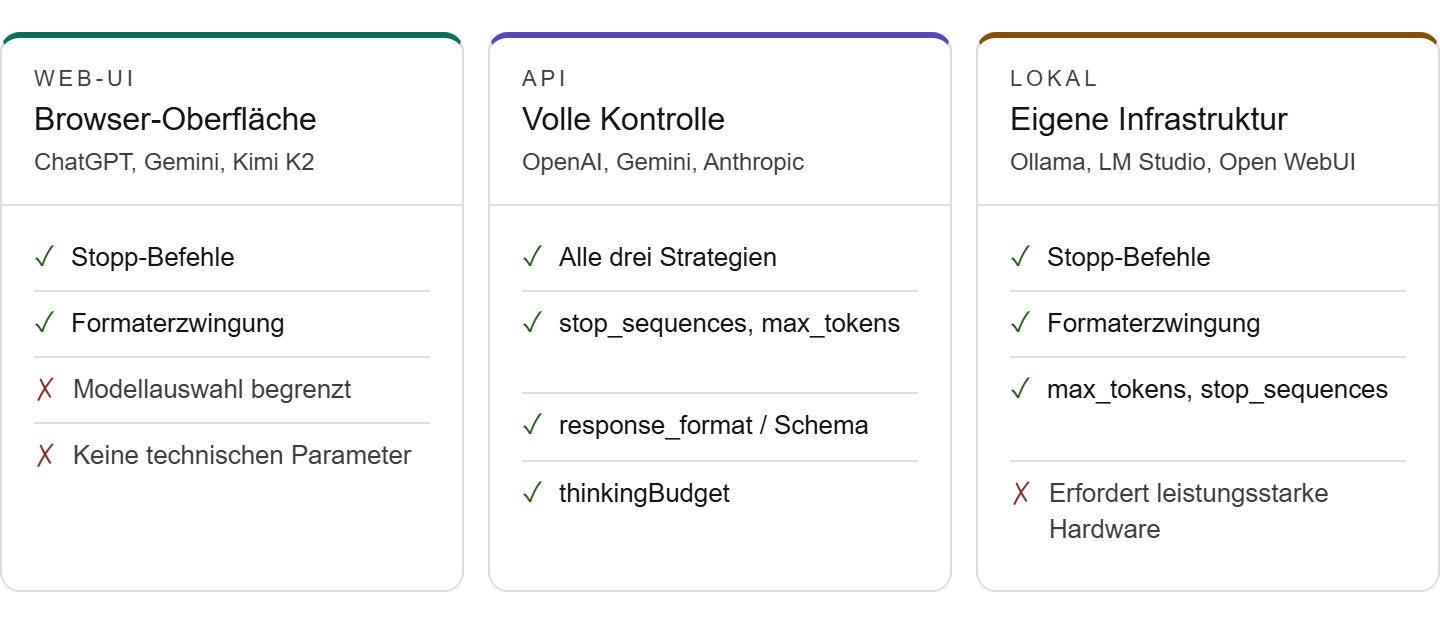
Die drei Massnahmen funktionieren in Web-UIs, Cloud-APIs und lokalen Setups. Unterschiedlich ist nur der Kontrollgrad.
In einer Web-UI lassen sich vor allem Prompt-Regeln und Formatvorgaben nutzen. In einer API kommen technische Limits, strukturierte Ausgaben, Logging und Kostenmessung hinzu. Bei lokalen Modellen hängt viel vom Inferenz-Stack ab.
Ollama ist niederschwellig und eignet sich gut für Einzelpersonen, Prototyping und kleinere Teams. Für skalierte, parallele Nutzung sind Server-Frameworks wie vLLM oft geeigneter, weil sie auf hohen Durchsatz und parallele Anfragen ausgelegt sind. Die Grundfrage lautet nicht „lokal oder Cloud?“, sondern: Welche Daten, welche Last, welche Latenz, welche Governance?
Bei Reasoning-Modellen kommt ein weiterer Hebel hinzu: die Steuerung der Denktiefe. Google dokumentiert etwa thinkingBudget für Gemini-Modelle; zugleich ist dieser Parameter modellabhängig und bei neueren Gemini-3-Modellen zugunsten von thinkingLevel nur noch eingeschränkt die bevorzugte Steuerung.
Was ist vLLM?
vLLM minimiert die Latenz und ermöglicht die gleichzeitige Bedienung hunderter Nutzer auf einer Instanz. Damit ist es im Vergleich zu Lösungen wie Ollama deutlich effizienter für skalierbare, kostensensible Unternehmenseinsätze.
Schweizer Rechtsrahmen: Effizienz ist auch Governance
Cloud-basierte LLM-Anwendungen berühren in der Schweiz das Datenschutzgesetz, sobald Personendaten verarbeitet werden. Der EDÖB weist ausdrücklich darauf hin, dass das Schweizer DSG auf KI-gestützte Datenbearbeitungen anwendbar ist. Werden Personendaten von Personen im EU-Raum verarbeitet, kann zusätzlich die DSGVO relevant werden.
Token-Optimierung ersetzt keine Datenschutzprüfung. Sie kann aber Teil einer datenschutzfreundlichen technischen Gestaltung sein: weniger unnötige Eingaben, weniger überlange Ausgaben, klarere Zweckbindung, bessere Protokollierung und kontrollierbare Formate. Das passt zum Grundsatz der Verhältnismässigkeit und zu technischen und organisatorischen Massnahmen nach DSG.
Für Behörden und regulierte Unternehmen ist zusätzlich zu klären, wo Daten verarbeitet werden. Bei Cloud-Diensten zählen Region, Auftragsbearbeitung, Logging, Datenresidenz, Unterauftragsverarbeiter und Löschkonzepte. Google beschreibt für Vertex AI, dass ML-Verarbeitung bei unterstützten regionalen Endpunkten innerhalb der gewählten Region oder Multi-Region erfolgt; solche Garantien müssen aber pro Dienst, Modell und Endpoint geprüft werden.
JSON oder XML?
JSON ist kompakt und der de-facto-Standard in modernen APIs — richtig für einfache, flache Strukturen. XML bietet mehr Flexibilität bei komplexen Verschachtelungen, unterstützt Attribute direkt im Tag und erlaubt eingebettete Kommentare. Für strukturierte Behördenanfragen mit Validierungsanforderungen ist XML die belastbarere Wahl. XSD garantiert dort, dass die KI-Antwort exakt der vorgegebenen Struktur entspricht.
JSON vs. XML einfach erklärt
Wie Computer Daten austauschen – im Alltags-Vergleich
Fallbeispiel: Was eine Messung zeigen kann
Ein mittelständisches Unternehmen im Grossraum Zürich nutzt ein Sprachmodell über API für Kundenservice, Dokumentation und Softwareentwicklung. Vor der Optimierung entstehen monatlich 2,5 Millionen Output-Tokens.
Die Optimierung erfolgt in drei Schritten:
- Stopp-Anweisungen und Längengrenzen für Standardantworten.
- Modell-Routing: einfache Aufgaben an schnelle Standardmodelle, komplexe Aufgaben an Reasoning-Modelle.
- Strukturierte Ausgaben mit JSON-Schema für automatisierte Workflows.
Nach vier Wochen sinkt der Output-Verbrauch im Beispiel auf 875’000 Tokens pro Monat. Das entspricht einer Reduktion um 65 Prozent. Gleichzeitig sinkt die durchschnittliche Antwortzeit, weil weniger unnötiger Text erzeugt wird und weniger Iterationsrunden nötig sind.
Diese Zahlen sind als Fallbeispiel zu verstehen, nicht als Garantie. Entscheidend ist die Methode: Vorher messen, Massnahmen einführen, nachher erneut messen.
Die Kosten des Nichtstuns
Viele Entscheider unterschätzen die Skalierung. Ein paar Rappen pro Anfrage wirken unbedeutend. Bei zehntausenden Anfragen pro Monat wird daraus ein Budgetposten.
Wenn ein Anwendungsfall 50 Millionen Output-Tokens pro Monat erzeugt, macht es einen erheblichen Unterschied, ob die Antworten knapp, strukturiert und passend modelliert sind, oder ob jedes Modell ungebremst formuliert. Bei GPT-4o nennt OpenAI für Output-Tokens 10 USD pro 1 Million Tokens; Beispielrechnungen müssen deshalb immer an Modell, Preisstand und Anbieter angepasst werden.
Für Behörden kommt ein zweiter Punkt hinzu: Nicht jede Einsparung ist nur finanziell. Kürzere, strukturierte, zweckgebundene Antworten sind leichter zu prüfen, zu protokollieren und in bestehende Prozesse einzubetten.
Der KI-Sprachvergleich im Detail
Zahlen und Hintergründe zur Abrechnung auf einen Blick
| Fokus-Prüfung | Deutsch | Englisch | Differenz | Bedeutung |
|---|---|---|---|---|
| Silben-Fragmente (Tokens pro 100 Worte) |
135–155 | 100–115 | +30 bis 40% | KIs zerlegen deutsche Wörter in viel kleinere Einzelteile. Das erzeugt künstlich mehr Abrechnungseinheiten. |
| Rohpreis (pro 1 Mio. Einheiten) |
ca. 13 CHF | ca. 10 CHF | +30% | Schon der nackte Basis-Einkaufspreis im Hintergrund ist für die deutsche Sprache teurer angesetzt. |
| Ø Wortlänge (Buchstaben pro Wort) |
11,6 Zeichen | 8,2 Zeichen | +41% | Unsere Wörter sind deutlich länger. Längere Wörter bedeuten automatisch mehr Textmasse für die KI. |
| Echter Endpreis (In der App gemessen) |
Praxis-Messwert | Basis-Referenz | +72% Aufpreis | Zusammengerechnet führt die Sprachstruktur dazu, dass deutsche Texte in der Realität fast Dreiviertel mehr kosten. |
Hinweis: Bei den Angaben handelt es sich um Praxis- und Messwerte. Der exakte Unterschied hängt vom verwendeten KI-Modell und dem jeweiligen Textaufbau ab.
Roadmap für Unternehmen und Behörden
Stufe 1: Sofortmassnahmen
Bestehende Prompts prüfen. Einleitungen, Wiederholungen und Schlussfloskeln entfernen. Antwortziel, Format und Abbruchbedingung festlegen.
Stufe 2: Modell-Routing
Aufgabenklassen definieren: Routine, Fachantwort, Analyse, Reasoning, Code, rechtlich sensible Fälle. Für jede Klasse ein Standardmodell festlegen und regelmässig testen.
Stufe 3: API- und Governance-Integration
Technische Limits setzen, strukturierte Ausgaben verwenden, Token-Verbrauch monatlich auswerten, Datenschutz- und Sicherheitsanforderungen dokumentieren.
Praxis-Checkliste
10 Fragen für effizientere KI-Anwendungen
Wer LLM-Kosten, Qualität und Governance verbessern will, sollte diese Punkte regelmässig prüfen.
Fazit
LLM-Effizienz ist Teil von Kostenkontrolle, Nutzererfahrung und Governance.
Drei Massnahmen wirken besonders stark: das richtige Modell für die richtige Aufgabe, klare Stopp- und Längenvorgaben sowie erzwungene Ausgabeformate. In der Praxis können dadurch erhebliche Einsparungen entstehen. Der Wert von bis zu 72 Prozent sollte jedoch als messbarer Spitzenwert aus konkreten Anwendungen verstanden werden.
Wer es umsetzt, gewinnt Kontrolle über Qualität, Kosten, Antwortzeiten und Datenflüsse. Genau das brauchen Unternehmen und Behörden, wenn KI vom Experiment zur Infrastruktur wird.
Über die Autorin
Manuela Frenzel arbeitet an der Schnittstelle von Journalismus, AI-Prompting und verantwortbarer lokaler KI. Als akkreditierte Journalistin und akademisch ausgebildete AI Prompterin analysiert sie, wie KI-Systeme Kommunikation, Arbeitsprozesse und Verantwortlichkeiten in Unternehmen verändern. Ihr Fokus liegt auf KI-Einordnung, lokalen KI-Anwendungen, Prompt-Architekturen und praxisnaher KI-Governance.